Can we record dreams? AsapSCIENCE hints at a promising positive answer!
No. But the probability of it being right could one day eventually be so close to 1, that we’d feel that it works perfectly! All thanks to the great potential of probabilistic algorithms!
Hehe. We’ll get there. First, let me talk a bit about the theory of probabilistic algorithms. Then, I’ll present the ideas behind the algorithm reconstructing dreams by its application to face detection. Finally, I’ll talk about probabilistic algorithms in quantum computing!
BPP
It’s a known fact that randomness can avoid the worst case time complexity for the quick sort, as you can read it in my article on divide and conquer. But that is just a glance of another powerful way of thinking: Think with randomness. This concept has led to the definition of $BPP$. $BPP$ stands for Bounded-error Probabilistic Polynomial. It’s the set of decision problems for which there exists a probabilistic algorithm that gives a wrong answer less than 1 out of 3 times, in a time that is always polynomial.
One very interesting result is that, no matter which positive (small) number you take, if a problem is $BPP$ then it can be solved in polynomial time with an error less than this number.
You can run the $BPP$ algorithm a great number of times and observe the returned answers. The probability of an error can be reduced to as low as you want. As this number of times does not even depend on the size of the inputs, the time needed will remain polynomial. In fact, by iterating a polynomial number of times of the size of the inputs, we can make sure that the error will be even smaller for large inputs.

Answering your question is equivalent to proving whether $P \neq BPP$, which is an open problem ($P$ is the set of deterministic polynomial algorithms, defined precisely in my article on P=NP). Obviously, any $P$ problem is a $BPP$ problem. The more interesting question is whether there exists a $BPP$ problem that is not $P$.
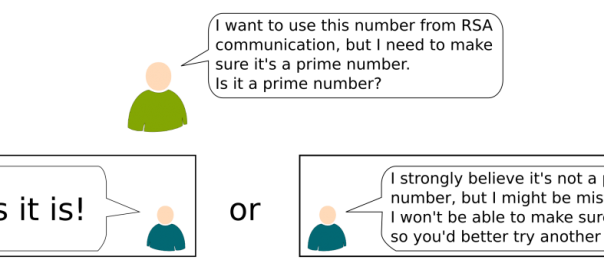
One important remark on that matter concerns the crucial primality test. The primality test is the problem of deciding whether a number is a prime number. It’s a very important problem because most cryptography technics on based on prime numbers. In particular, the RSA system requires the generation of prime numbers with hundreds of digits. Not only have $BPP$ algorithms been found for the primality test, but they actually are the one used today for cryptography!
That would terribly bad! Fortunately, the primality tests that are used never make an error when saying that a number is prime. The error they may do is by saying that a number is not prime, where in fact there is a chance that the number was actually prime. Don’t worry, your messages are well encrypted.

For a long, there was no known polynomial primality test, and people therefore conjectured that $P \neq BPP$. However, in 2002, a polynomial primality test algorithm has been found by Manindra Agrawal and his students Neeraj Kayal and Nitin Saxena. Can you imagine that? This incredibly crucial problem only found an answer that late! In practice though, this algorithm is still too long to be used.
The story of the primality test has led scientists to conjecture that $P=BPP$, which would mean that there is no major gain with randomness. Still, at least so far, many problems are rather solved with probabilistic algorithms because these algorithms are much faster, despite not being always exact.
Classifiers for Face Detection
Let’s now head back to the problem of face recognition. I’ll keep showing the interest of thinking with probabilities, as I’ll give you an introduction to how the algorithms of face recognition work. Well, actually, since face recognition is not that successful yet (at least on iPhoto in 2012), I’ll talk about face detection, which was first introduced by Viola and Jones, and is now done pretty well.
The first step of face detection is an analysis of the properties of the picture on which you are trying to detect faces. In order to do quick computations, these properties are very simple features of rectangular zones of the pictures. They are known as Haar-like features, and are calculated with Haar wavelets.
A Haar wavelet is a division of a rectangular zone of a picture into sub-rectangles. Each sub-rectangles is either white or black. The following picture displays classical Haar wavelets:


Now, for each zone and each Haar wavelet, we are going to compute simple properties. For instance, we can compute the difference between the total luminosity of the white sub-rectangles and the total luminosity of the black sub-rectangles. This gives us Haar values that describe the zone of the picture.
Now, these Haar values are compared to the Haar values we should obtain if the zone corresponds to a face.
This is where the probabilistic reasoning starts! Your two questions are actually very linked. The way we know the Haar values we should obtain is intrinsically related to the way we are going to compare them. The best-known method is called AdaBoost.
The idea is to use classifiers. Each classifier is a test we can do on Haar values. A classifier is good if the answer of the test is very frequently right. But it’s hopeless to find such classifiers which are simple. That’s why, we’ll search for simple weak classifiers, that is, classifiers for which the answer of the test is right for face detection more than half of the time.
Indeed. Yet, for $BPP$ algorithms to be very often right, we need to run them several times.
Yes we can! That’s actually how things are done with AdaBoost! This has enabled real-time face detection in cameras. Impressive, right?
Constructing good weak classifiers is crucial for face detection. This problem has been solved simply by observing the way humans actually detect faces. We do that by experience. Similarly, machine learning is used to search for weak classifiers. Basically, two sets of images are used. The first set only contains pictures of faces. The second one doesn’t have any picture with a face. Now, AdaBoost proposes also a method that constructs weak classifiers, based on Haar values of the images and the fact that they contain faces or not.
My point here is that thinking with randomness is very powerful.
Hehe… I’m not actually sure if these weak classifier technics are used to reconstruct dreams but I’d bet they are. Now, instead on working with Haar values for images, we use other measurements of brain activities to create weak classifiers.
And we might be able to go even further with quantum mechanics!
BQP
Because I want to talk about a second important open problem in computer science: $NP=BQP$? $NP$ is the set of Non-Deterministic Polynomial problems, which, in fact, has nothing to do with probabilistic algorithms. It’s quite a complicated concept, which I define in my article on P=NP. $BQP$ is the set of decision problems that can be solved in a polynomial time, with a bounded error (just like $BPP$) on a quantum computer.
OK, let’s get back to quantum theory. In this theory of physics that describes amazingly well behaviors of particles, each particle can be simultaneously in several states. Its spin, which is one of its characteristic, can be both up and down. When we observe the spin, it takes a value, either up or down, but the way the value is chosen is not deterministic. As a matter of fact, if we repeat the experience, we can get the opposite result. In fact, the value it’s going to take can be described with a probabilistic distribution, which can be calculated with the wave function. Wave functions play a key role in this theory, as well as probability. Find out more with my articles on quantum mechanics and on the dynamics of the wave function.
First, let me talk about how operations are made in common computers. Data in common computers are stored into sequences of bits. A bit is a value that can be either 0 or 1. Operations are therefore operations between 0 and 1. But there aren’t that many operations that can be made with 0 and 1. You can do 0+0, 0+1, 1+1, 0*0, 1*0, 1*1… well that’s basically it.
The idea of quantum computers, introduced by the Nobel Prize laureate Richard Feynmann in 1982, is no longer to do operations on the value of the spins (in usual computer, this would correspond to operations on bits whose values are 0 or 1), but to do operations on the wave functions describing the spins. Yet, wave functions are extremely precise objects, with which you can do complicated operations than 1+1 like with bits. The wave function corresponding to the spin of a particle is called a qubit. What makes it extremely powerful is then that the qubits of $n$ particles include $2^n$ degrees of freedom, as the wave functions are combined and not independent, as opposed to bits.
No. When we want the answer of the algorithm, we need to take a measure of the spin of particles. This corresponds to observing one possible result of a probabilistic distribution. That means that the result is necessarily random. Thus the definition of BQP. The following video on Veritasium details more of the technical details of spins and quantum computing.
Yet a few quantum computers have already been created. They only use a few qubits (I’ve read about a 14 qubit quantum computer…). The problem they face is mainly about decoherence. Yet, although actual quantum computers are still in the early phase of development, a few amazing BQP algorithms have already been found. In particular, Peter Shor has come up with a BQP algorithm that solves the factorization problem. Yet, the RSA system is mainly based on the assumption that no one will be able to solve this problem in polynomial time. Learn more with Scott’s articles on the RSA system and quantum cryptography.
The relationship between NP and BQP is quite a mystery. We don’t even know if one is included in the other. One result though is the fact that any problem solved with a quantum computer with a bounded error can be solved with a Turing machine (although it may take a while).
Let’s sum up
Thinking with randomness is amazing. In fact, as quantum theory is suggests it, our understanding of the universe relies on an accurate understanding of probabilities. This understanding has enabled us to assert with good confidence the detection of the Higgs boson. According to the standard model, a Higgs boson could be generated by particles collision at high energy. But its appearance is actually not guaranteed. It is probabilistic. Just like for $BPP$ algorithms, scientists therefore had to repeat the experiment a very high number of times to assert its existence. But we’re not totally sure of that. The experiment only proves that the likelihood of a mistake is less than one of a billion…
In my PhD research, I am working on mechanism design, where a regulator defines a system of interaction between agents, whose private information is modeled by a probabilistic distribution. This induces a bayesian game. I use algorithms based on probabilistic reasonings to search for Bayesian-Nash equilibrium. This shows the increasing importance of probabilistic algorithms.
Leave a Reply